AI Campaign Automation: Why Setup Quality Determines Scaling Outcomes
Most marketers assume automation improves performance over time. Early inefficiencies should self-correct as more data flows through the system. The model learns, signals strengthen, and outcomes move upward.
That assumption breaks under AI campaign automation.
Most AI marketing automation tools do not gradually refine early decisions. It accelerates them. Setup choices made before the first impression is served define the structure of optimization long before scaling begins.
Once the system starts learning, it quickly locks into early patterns instead of questioning them. It keeps repeating what seemed to work first, rather than finding the best possible outcome. This means performance depends heavily on those initial signals, which are often hard to see or fix later when teams try to step in.
This blog explains how AI campaign automation moves from setup to scaling, why early decisions are persist, and where teams lose control over it.
Why Setup Defines Optimization Boundaries
Automation systems begin with predefined inputs: audience segments, creative variations, conversion event definitions, and bid constraints. The system does not generate these inputs. It operates within them.
Initial conditions are not just starting points. They are the constraints that define what the system can explore during optimization. Because the system selects from available options, it cannot discover performance that exists outside those boundaries. It can optimize within the defined space. It cannot expand the space itself.
This has a direct consequence. If high-intent users are grouped with low-intent users inside the same audience segment, the system learns an average response to that segment. Strong signals from valuable sub-groups get suppressed. The system never isolates them, not because it lacks the intelligence to do so, but because the setup does not create the structure that would allow it.
The same logic applies to creative classification. If a strong creative is grouped with weaker variations under the same tests, the system evaluates them together before it can distinguish between them. By the time differentiation is possible, the learning cycle has already moved on.
Setup quality does not just affect early performance. It defines what the system is allowed to learn.
How Compressed Feedback Loops Learn Early Errors
Once campaigns go live, the system begins rapid signal processing. Automation reduces the time between action and evaluation, which is one of its primary advantages. But compression has a structural side effect that most teams do not account for.
A feedback loop is the cycle where the system observes outcomes, updates its internal model, and adjusts future decisions. Because automation accelerates this cycle, early data carries disproportionate weight. The system updates quickly, but it does not pause to reassess foundational assumptions before updating.
This creates an asymmetry: the speed that makes automation efficient but also makes it resistant to correction.
Consider what happens with creative performance in the first 48 hours of a campaign:
A weak creative that generates early engagement, even low-quality engagement, receives more exposure based on initial signals
A strong creative that starts slow, perhaps because it targets a narrower audience or a longer decision cycle, loses visibility before it can accumulate sufficient data
The system interprets the absence of an early signal as poor performance, not as insufficient data
The feedback loop does not distinguish between "this performed badly" and "this did not have enough time to perform." Both produce the same output: reduced allocation. And once allocation drops, the creative loses the exposure needed to generate the data that would correct the classification.
Early misclassification does not get overwritten by better data. It gets reinforced by the decisions it triggers.
Path-Dependency Problem in Scaling
Path dependency in AI campaigns refers to a system’s tendency to learn patterns early, making future optimization outcomes dependent on initial setup conditions rather than performance reality.
After the initial learning phase, teams typically increase the budget to scale what appears to be working. This is where path-dependency becomes a direct performance constraint.
Scaling works well only if the system has learned the right patterns. If those patterns are accurate, scaling boosts performance.
But if the early signals were flawed, like noisy data, wrong audience segments, or poor creative evaluation, scaling doesn’t improve results. It just amplifies those mistakes.
It increases exposure to the same patterns that the learning phase embedded.
The system allocates more budget toward previous decisions, and those decisions continue to execute at a greater scale. The inefficiency that existed at a low budget now runs at a high budget. Performance may hold initially, but the system is doing exactly what it learned to do, and the ceiling is lower than it should be, and the path toward a higher ceiling has been progressively narrowed by each scaling decision built on top of it.
Setup Quality | Early Signal Accuracy | Long-Term ROAS Trajectory |
|---|---|---|
High segmentation clarity | Strong, distinct signals | Sustained growth with stable efficiency |
Moderate segmentation overlap | Blended, averaged signals | Plateau after initial gains |
Poor segmentation structure | Noisy, misleading signals | Early spike followed by consistent decline |
The result in outcomes is not proportional to the setup quality. Small differences in how segments are defined or how creative tests are structured produce large gaps in long-term performance. This is the characteristic signature of path-dependent systems: sensitivity to initial conditions that compounds over time rather than averaging out.
Why Standard Scaling Interventions Fail
Teams using any marketing automation platform that encounter flat performance typically respond with a predictable set of tactics: new creatives, expanded audiences, shifted budgets, and restructured ad sets. These interventions assume the system will adapt to new inputs and update its patterns accordingly.
That assumption underestimates how path-dependent learning systems handle new information.
When new inputs enter a system that has already completed its primary learning cycle, those inputs compete with established patterns that carry accumulated confidence. The system does not evaluate new signals and old signals equally. It weighs new signals against the baseline of what it already knows, which was formed under conditions that may no longer reflect current performance reality.
This creates a slow-adoption problem for new inputs. A new creative variation must accumulate enough signal to shift system confidence away from an established pattern. That process takes time and budget. During that period, the new variation is being evaluated against a baseline that may itself be flawed, making it harder to demonstrate genuine performance rather than relative performance against a weak incumbent.
The system is not broken. It is doing exactly what it was designed to do: maintain consistency in learned patterns. The problem is that consistency and adaptability are in structural tension inside path-dependent optimization systems.
How the Setup-to-Scaling Progression Actually Works
The Setup-to-Scale Loop
SETUP → SIGNAL → REINFORCEMENT → SCALE
Early inputs define the signal space, signals shape allocation, allocation reinforces patterns, and scaling amplifies those patterns.
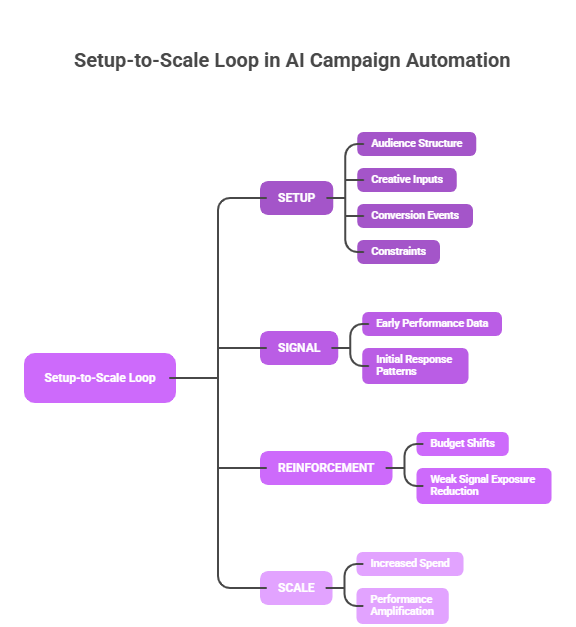
Tracing how automation moves from initial setup to full-scale deployment makes the path-dependency mechanism concrete:
Input definition: The system receives audience definitions, creative variants, event structures, and bid parameters. These define the exploration space.
Signal weighting: Early performance data is evaluated. Relative weights are assigned to each input based on initial response patterns.
Budget reallocation: Spend shifts toward inputs with stronger early signals. Lower-performing inputs lose exposure before their patterns can stabilise.
Pattern reinforcement: Repeated exposure to high-weighted inputs generates more data for those inputs, further strengthening their confidence scores relative to deprioritised alternatives.
Scaling: Budget increases are applied to the reinforced pattern set. The system scales what it learned, not what is optimal in the current environment.
This is the core mechanic of digital marketing automation: each step builds on the previous one without revisiting foundational inputs. The system does not revisit step one from step five. The starting structure persists through scaling, not because it cannot be changed, but because the architecture is designed to build forward, not backward.
Platforms like Maino.AI approach this by separating decision logic from execution, the system determines what adjustments should happen across campaigns, while each channel executes based on its native signals. That separation creates intervention points where path-dependent decisions can be overridden without requiring a full campaign reset.
Where Automation Breaks Under Real Campaign Conditions
The path-dependency problem is most visible in three specific scenarios, each of which exposes a different failure mode of the setup-to-scaling architecture.
Low data density in early phases.
When conversion volume is low at launch, common in early-stage campaigns or niche audience structures, the system makes high-confidence decisions based on statistically thin signals. These decisions get reinforced before they can be validated. The feedback loop compresses faster than evidence accumulates.
Rapid market or behavioral shifts.
Automation performs best under stable conditions where learned patterns remain valid. When competitive dynamics shift, creative trends change, or audience behavior moves quickly, the system continues optimizing based on a model of reality that no longer applies. It does not detect the shift, it experiences the signal decay from the shift as noise and filters it out.
Overlapping or ambiguous audience structures.
When segments share significant overlap, signal attribution becomes unreliable. The system cannot cleanly distinguish between which segment drove a conversion. Learning becomes blended, and optimization allocates budget toward the composite signal rather than the strongest individual segment within it.
In each of these cases, the problem is not that automation is being misused. It is that automation was applied to a setup that could not support the assumptions the learning architecture requires to function correctly.
How These Changes Campaigns Should Be Managed
Understanding path-dependency as a structural property, not an edge case, changes how automation in digital marketing should be approached.
Setup is not a preliminary step. It is the primary strategic input. Decisions made before the first impression determine the ceiling of what scaling can achieve. Teams that treat setup as a configuration task and strategy as something that happens during optimization have the sequence inverted.
Performance plateaus are often structural, not tactical. When scaling stops producing proportional returns, the instinct is to iterate on creative or targeting. If the plateau is caused by path-dependent learning embedded in early setup decisions, those iterations will continue to underperform until the foundational structure is reset.
Automation and manual control are not opposites. The scenarios where automation breaks low data density, rapid shifts, ambiguous segments are precisely the scenarios where human intervention has the highest impact. The decision of when not to let the system run is as consequential as the decision of when to let it.
Signal quality at setup determines whether the system learns something real or something fast. In path-dependent systems, fast and real are not the same thing.
Frequently Asked Questions
Why does campaign performance plateau after scaling?
Scaling increases exposure to the patterns the system reinforced during the learning phase. If those patterns were formed on blended or noisy signals, scaling amplifies the inefficiency rather than the performance. The system is not discovering new growth, it is scaling a ceiling that was set during setup.
How important is initial setup in AI-driven campaigns?
In AI based digital marketing Initial setup defines the boundaries of what the system can optimize. It cannot discover performance outside the structure it was given. Poor segmentation, ambiguous event definitions, or poorly structured creative tests constrain learning in ways that compound over time rather than correct themselves.
Can AI correct poor campaign setup over time?
Not reliably. Compressed feedback loops cause early signals to carry disproportionate weight. Later signals compete against established patterns with accumulated confidence. The system can adapt incrementally, but it cannot restructure its foundational assumptions without manual intervention or a learning reset.
When should teams not rely on full campaign automation?
When conversion signal density is low, when audience structures are ambiguous, or when market conditions are shifting faster than the learning cycle can track. In these scenarios, full automation optimizes toward the wrong patterns with increasing confidence. Staged or manually constrained automation produces more reliable outcomes.
Why do new creatives and audience expansions fail to fix performance plateaus in automated campaigns?
Because new inputs must compete against established patterns that carry accumulated confidence. The system weights them as lower-confidence alternatives to existing decisions. They require significant exposure to shift system behavior and that exposure must happen within a learning environment that is already biased toward earlier patterns.