
How AI Handles Bidding and Optimization Decisions at Scale
Most teams assume automated bidding systems are trying to chase the highest possible return on every impression. That assumption is easy to make, the system has access to performance data, it learns continuously, and it should be routing spend toward whatever works best.
That is not what these systems are doing.
Ad auctions fluctuate constantly. Competitor bids change within seconds. User intent shifts across sessions. Pricing adjusts based on real-time supply and demand across millions of simultaneous auctions. In that environment, a strategy that maximizes ROAS at one moment can collapse in the next if conditions shift before the next bid fires.
AI bidding systems do not aim for the highest return. They aim for the most stable return under uncertainty. That distinction changes how bids are calculated, where budget flows, and why segments that appear to be strong performers often receive less spend than teams expect.
Why Auction Volatility Makes Consistent Return Maximization Unstable
Every bid enters a dynamic auction where outcomes are probabilistic, not fixed. The same segment can produce dramatically different returns across consecutive impression cycles depending on who else is bidding, what signal the platform is reading from the user, and how demand is distributed across the inventory pool at that moment.
Auction volatility is the degree of fluctuation in price and performance outcomes within this environment. It is not a marginal factor. It is the structural condition that every bidding system operates under.
The implication is significant. If a system attempts to maximize return at each decision point without accounting for volatility, it will inevitably take aggressive positions in high-variance environments and those positions will produce large, unpredictable swings in aggregate performance. The system might hit a strong return on a given day and a weak return the next, not because targeting or creative changed, but because the auction environment shifted underneath a strategy that was not designed to account for that kind of movement.
At small scale, this variability is tolerable. At large scale, it is not. Small inefficiencies amplify quickly when budget is large. A volatility exposure that produces a 10% performance swing at a $10,000 weekly budget produces the same proportional swing at $500,000 but the absolute impact is fifty times larger.
This is why large-scale AI bidding systems do not simply optimize for expected return. They optimize for expected return relative to its variance.
What Risk Modeling Actually Does Inside a Bidding System
The Risk-Adjusted Bidding Model
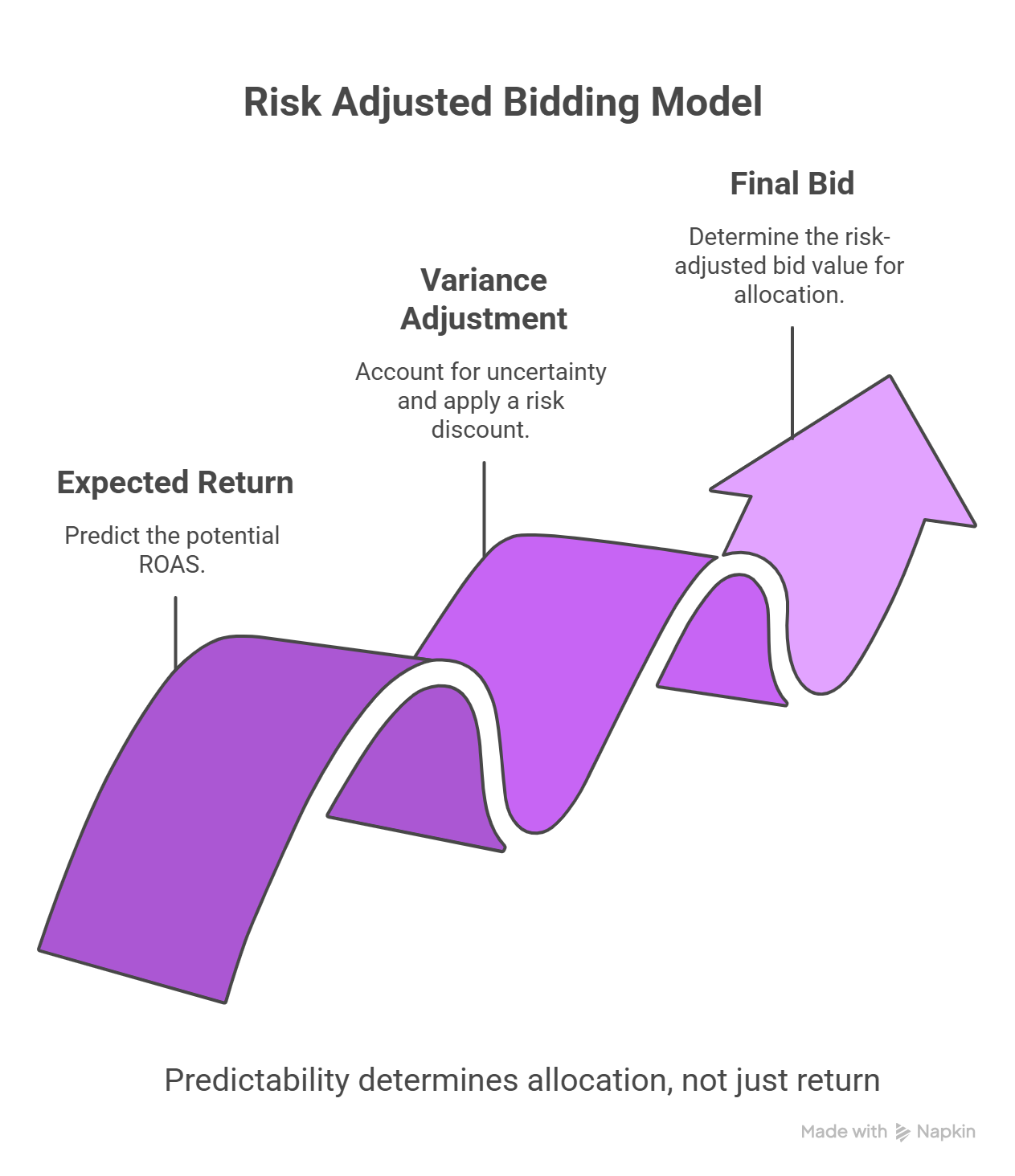
Expected Return Predicted ROAS for a given impression or segment
Variance Adjustment Discount applied based on outcome uncertainty
Final Bid Risk-adjusted value the system is willing to pay
Key Principle: Higher return does not guarantee higher bids, predictability determines allocation.
Before any bid is placed, the system is not just asking "what return can this impression produce?" It is asking a second question: "how reliably can this impression produce that return?"
This is risk modeling: the process of evaluating uncertainty in expected outcomes before taking action. The two inputs are expected ROAS and variance. Expected ROAS is the mean return the system predicts for a given segment under current conditions. Variance is the spread of possible outcomes around that mean.
A segment with moderate expected ROAS and low variance produces predictable, consistent returns. A segment with high expected ROAS and high variance produces strong returns sometimes and weak returns other times with the frequency and magnitude of each outcome being genuinely uncertain.
When the system weighs these two inputs together, the moderate-ROAS, low-variance segment can score higher than the high-ROAS, high-variance segment. Not because the system is being conservative. Because at scale, the aggregate performance of a portfolio of predictable bids consistently outperforms the aggregate performance of a portfolio of high-upside, high-risk bets, particularly when losses in volatile segments are not bounded by the upside they promise.
The system is not missing the high-return opportunity. It is making a deliberate trade-off between peak performance in a given segment and stable performance across the full campaign portfolio.
How Variance Thresholds Shape Bid Suppression
The practical output of risk modeling is bid suppression, a mechanism where the system reduces bids below what expected ROAS alone would justify, specifically because variance in outcomes exceeds a defined threshold.
This behavior is counterintuitive when teams observe it from the outside. A segment appears to be performing well. Expected returns are strong. But the system is allocating less budget there than the apparent opportunity warrants. The instinct is to interpret this as a system error, an overly conservative model that is failing to capitalize on something real.
In most cases, it is not an error. It is the variance threshold in operation.
Bid Environment | Expected ROAS | Variance Level | System Behavior |
|---|---|---|---|
Brand search queries | Moderate to high | Low | Bids aggressively: high confidence in outcome stability |
Retargeting segments | High | Moderate | Bids steadily: balances return with manageable variance |
Broad prospecting audiences | High potential | High | Suppresses bids: variance exceeds return justification |
New audience experiments | Uncertain | Very high | Minimal allocation: insufficient signal to model risk |
The pattern that emerges is not about return levels. It is about the relationship between return and predictability. Brand search queries receive aggressive bids despite moderate ROAS because outcomes are consistent. Broad prospecting receives suppressed bids despite high potential ROAS because outcomes are not.
Teams that evaluate bidding decisions only through an expected-ROAS lens will consistently misread this behavior as underperformance. The system is not failing to find the opportunity. It is declining to take a position it cannot model with sufficient confidence.
Why Stability Dominates Optimization at Scale
The preference for stability over peak performance is not a quirk of any particular bidding system. It is a mathematical consequence of operating at scale under uncertainty.
As budget scales, two things happen simultaneously. First, the system is exposed to a larger number of auctions, which means a larger number of volatile outcomes if it is participating aggressively in high-variance environments. Second, the cost of a performance swing becomes larger in absolute terms, even if the percentage impact remains constant.
A system that chases peak returns in individual segments can produce strong results in any given reporting window. But over time, the variance it accumulates produces downside events that erode the gains from the peak periods. The aggregate outcome, what performance looks like across weeks and months rather than individual days, is lower than it would be under a stability-first approach.
This is why AI bidding systems that operate at genuine scale shift their optimization target from maximizing ROAS to minimizing variance while maintaining acceptable efficiency. The goal is not the highest possible return in the best moment. It is the most consistent return across the full range of moments, including the volatile ones.
Platforms designed around this model, like Maino.ai, structure the decision layer separately from the execution layer. The system determines what risk-adjusted position to take across the portfolio; each platform executes within its native auction environment without requiring the decision layer to abstract away platform-specific signal quality. This separation maintains stability at the portfolio level while preserving the signal richness that each platform's native bidding infrastructure requires.
Why Manual Bid Overrides Tend to Reduce Efficiency
When teams observe bid suppression in segments that appear to be performing, the natural response is to intervene. Bids are increased manually. Budget caps are adjusted. The system's conservative positioning gets overridden in favor of what looks like a missed opportunity.
These interventions almost always introduce more volatility than they capture in upside.
The reason is that manual overrides bypass the variance modeling layer. A team increasing bids in a high-performing segment is responding to expected return data, what the segment has produced in the past. The system's suppression decision was based on variance data, what the segment's outcomes look like across the full distribution, not just the recent average.
When a manual override pushes bids into a high-variance segment without the system's risk adjustment in place, the campaign takes on the full volatility of that environment. Short-term gains may appear, the segment was performing well recently, which is why the override was made. But the distribution of outcomes has not changed. The volatile segment continues to be volatile. And now the campaign is exposed to the downside of that volatility without the portfolio-level protection the system had structured around it.
Manual intervention in automated bidding is most disruptive not when it changes the outcome, but when it dismantles the risk structure the system built to protect aggregate performance.
Where Automated Bidding Breaks Down
The stability-first architecture that makes AI bidding reliable at scale also creates specific failure conditions that teams need to understand.
Insufficient conversion volume. Risk modeling requires enough data to estimate variance reliably. When conversion volume is low early in a campaign, in a niche segment, or after a significant structural change, the system's variance estimates become unreliable. In this state, the system may suppress bids in strong segments because it cannot distinguish between genuine volatility and statistical noise from a small sample. Scaling spend in low-data environments does not resolve this, it gives the system more budget to allocate on an unreliable model.
Rapid shifts in market conditions. Variance estimates are built from historical signal patterns. When competitive dynamics shift suddenly a major competitor enters or exits, a platform changes its auction mechanics, or user behavior moves quickly, historical variance patterns no longer reflect current reality. The system continues optimizing against an outdated model of the auction environment while actual performance diverges from its predictions.
Extreme niche variability. Some high-value segments are structurally high-variance, not because the opportunity is weak, but because conversion events are sparse and the signal density required for reliable risk modeling does not exist at the audience size available. These segments can be genuinely strong performers that the system consistently underfunds. They require controlled manual exploration separate from the core campaign structure, not overrides inside it.
In each case, the failure is not in the bidding logic itself. It is in the conditions under which the bidding logic is being asked to operate, conditions that violate the assumptions the system was built to work within.
How This Should Change Campaign Decisions
Understanding that AI bidding optimizes for stable returns rather than peak returns changes how teams should interpret system behavior and structure their interventions.
Bid suppression is not a signal to override. When the system reduces bids in a segment that appears to be performing, the first question should be about variance, not about return. If the segment has high historical variability, the suppression is functioning as designed. If variance is genuinely low and expected ROAS is strong, that combination warrants investigation, but through structured testing, not a manual override inside the live campaign.
High-variance segments require isolation, not integration. Opportunities that carry high potential return alongside high outcome variability are best explored in controlled test environments with explicitly bounded budgets. Running them inside core campaigns forces the system to either take on their volatility or suppress them, neither of which produces optimal outcomes. Treating them as separate experiments preserves both the exploration and the stability of the core portfolio.
Manual intervention is most appropriate at the structural level. Changing audience definitions, restructuring creative tests, or adjusting campaign architecture creates conditions the system adapts to cleanly. Changing bid values or budget allocations inside an already-optimizing system disrupts the risk model without changing the underlying structure that produces the behavior teams are trying to modify.
The system is managing risk across thousands of decisions simultaneously. Teams that align their interventions with that logic, working on structure rather than against automated positioning, operate more effectively within it.
Frequently Asked Questions
Why does AI bidding avoid high-performing segments? Expected return is only one input into a bid decision. The system also models variance in outcomes for each segment. High-performing segments frequently carry high variance, the returns are strong on average but unpredictable across individual auctions. When variance exceeds the system's threshold, bids are suppressed even if expected ROAS is attractive. This is a deliberate risk-adjusted decision, not a missed opportunity.
How does the system actually calculate bid amounts? Bids are calculated based on a combination of expected ROAS and a variance penalty. The higher the variance, the more the system discounts the expected return when determining bid value. The result is a risk-adjusted bid that reflects not just what the segment might produce, but how reliably it produces it.
When should teams not rely on automated bidding? When conversion signal density is insufficient to model variance reliably, early-stage campaigns, niche segments, or periods following significant structural changes. When market conditions are shifting faster than the system's historical variance estimates can track. And when a genuinely high-value, high-variance opportunity exists that the system will systematically underfund, in which case manual exploration in an isolated test environment is more appropriate than forcing the system to handle it inside a stability-optimized campaign.
Does AI optimize for ROAS or stability? For stable ROAS, which is meaningfully different from maximum ROAS. The system targets consistent performance across the full campaign portfolio, not peak performance in the best-case segments. At scale, the aggregate outcome of consistent returns across many decisions outperforms the aggregate outcome of maximum returns in favorable conditions paired with volatile returns in unfavorable ones.
Why do manual bid increases often reduce long-term performance? Because they bypass variance modeling. A manual increase responds to expected return data, what the segment has recently produced. The system's suppression decision was based on the full distribution of outcomes, not just the recent average. Overriding the suppression exposes the campaign to the downside of that distribution without the risk structure the system had built to contain it.